Develop a cloud-agnostic app to connect Amazon S3 and Google Cloud Storage buckets
By Kumaraswami Muthuswami, SADA Senior Cloud Infrastructure Engineer
It’s become increasingly common to transition between cloud platforms such as GCP, AWS, and Azure. These shifts are driven by various factors including cost considerations, performance optimization, and the unique features offered by each cloud provider.
When companies switch from one cloud provider to another, they’re able to leverage numerous cloud-agnostic tools and technologies in the market that assist in migrating infrastructure, data, and CI/CD pipelines seamlessly. However, application migration presents a more complex challenge. It often entails either a complete app refactoring or redesign due to varying dependencies or API discrepancies between cloud platforms.
There are various approaches to tackle this challenge, such as utilizing conditional beans in Spring Boot, a method widely employed in such scenarios. However, I’ll illustrate an exceptionally effective method we recently employed for a client. They sought to migrate their AWS-based app to GCP while simultaneously maintaining cross-cloud access (hybrid mode) until the transition was complete.
The strategy involved implementing a common framework that dynamically determines dependencies based on the cloud platform where the app is deployed. This framework enables the creation of a cloud-agnostic app capable of running seamlessly in both cloud environments, allowing access to resources across clouds in hybrid mode. To achieve this, we segregated the implementation into a separate project, which functions as a library integrated into the microservices. This library intelligently determines the required cloud resources based on environment configurations at runtime.
Let’s dive into the details:
High-level diagram
Design and implementation
Common library
We’ll create a common library for microservices to ensure uniform implementations and streamlined dependency management. Its purpose is to establish a consistent framework across all microservices. This library:
- Inherits crucial Spring Boot dependencies to maintain consistency.
- Manages dependencies for microservices, enabling centralized updates from a single location when necessary.
- Encompasses standard beans, utilities, and endpoints essential across all microservices.
- Contains optional utilities that can be utilized based on specific needs.
- Offers common configuration classes to enforce uniform and standardized implementations.
Design pattern
The solution is designed using the factory design pattern.
The factory design pattern advocates coding for interfaces rather than implementations. By abstracting the instantiation of actual implementation classes from client code, this pattern enhances the robustness of our codebase, reduces coupling, and simplifies extensibility.
Tech stack
- Java
- Spring Boot
- Google Cloud Storage (GCS)
- Amazon Simple Storage Service (Amazon S3)
- Maven
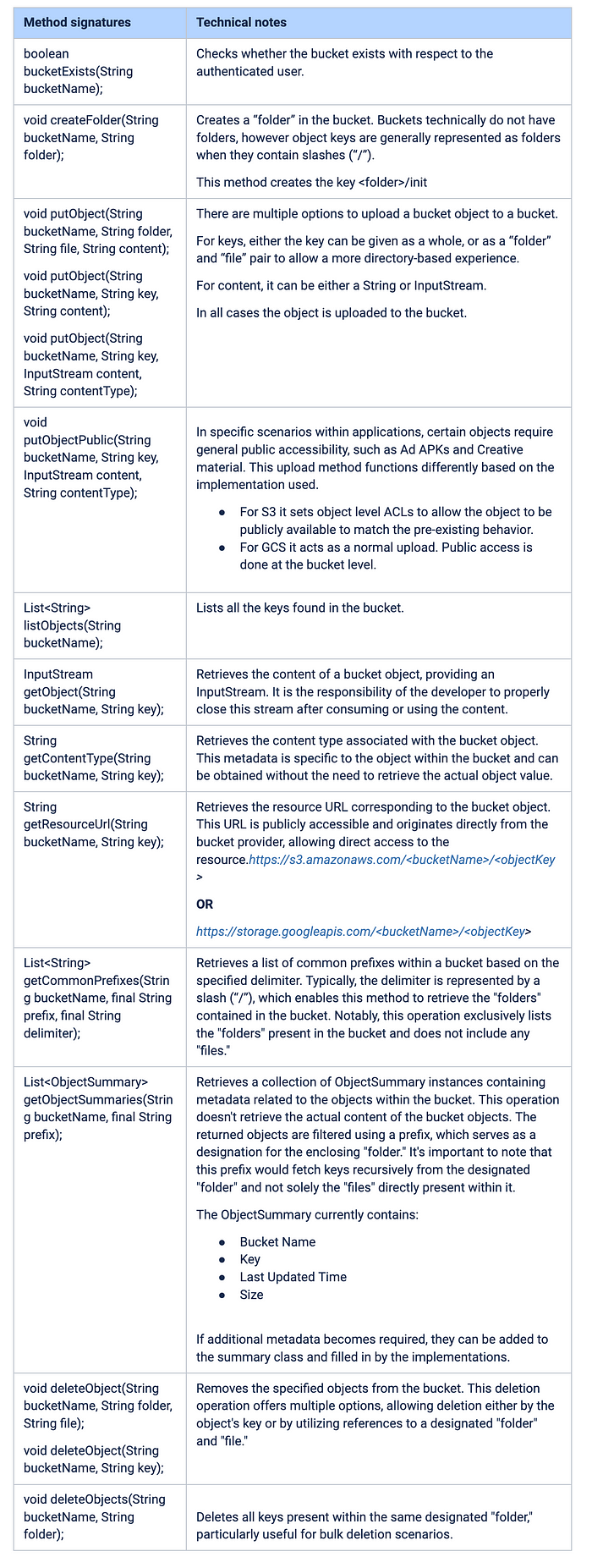
Implementation
The solution involves crafting a generic BucketService interface within the common library, featuring two distinct implementations: one utilizing the Amazon S3 client and the other employing the GCS client. To facilitate this, a builder was developed to accept a newly created BucketConfig, a typesafe configuration, and dynamically output the required BucketService implementation at runtime.
@Bean
public BucketService bucketService() {
return new BucketServiceBuilder(typesafeConfig.getBucket()).build();
}The implementation of BucketService incorporates the following functionalities to meet these requirements:
In this example, the application utilizes TypesafeConfig to manage environment variables. Within TypesafeConfig, the application incorporates a POJO (Plain Old Java Object) class named BucketConfig.java. This class includes various fields such as bucketName, keyPrefix, key, gcpProjectId, and awsRegion to encapsulate different configuration details.
The BucketConfig class serves to hold specific values based on the designated cloud environment. For instance, the Typesafe configuration file will contain the awsRegion detail for AWS deployment and the gcpProjectId for GCP deployment.
When the application passes the BucketConfig object to the common-lib, the BucketService, implemented within the common-lib, retrieves the values from the BucketConfig. Subsequently, based on these values, the BucketService dynamically constructs the connection object. For example, if the bucketConfig contains the gcpProjectId, the BucketService constructs the GCS (Google Cloud Storage) bucket object. Conversely, if the awsRegion is present in the bucketConfig, it builds the S3 bucket object accordingly.
Code snippet
TypeSafeConfig
public class BucketConfig {
/* The name of the bucket to use */
private String bucketName;
/* The prefix applied to all objects, often used as a "folder" */
@Optional
private String keyPrefix;
/* The key for the object in the bucket */
@Optional
private String key;
/* The GCP Project ID for the gcs client */
@Optional
private String gcpProjectId;
/* The AWS region for the S3 client */
@Optional
private String awsRegion;Bean Creation
@Bean
public BucketService bucketService() {
return new BucketServiceBuilder(typesafeConfig.getBucket()).build();
}BuckerServiceBuilder
public BucketService build() {
if (!Strings.isNullOrEmpty(bucketConfig.getGcpProjectId())) {
Storage storage = StorageOptions.newBuilder().setProjectId(bucketConfig.getGcpProjectId()).build().getService();
return new GCSBucketService(storage);
} else {
AmazonS3 amazonS3 = AmazonS3ClientBuilder.standard().withRegion(bucketConfig.getAwsRegion()).build();
return new S3BucketService(amazonS3);
}
}BucketService
public interface BucketService {
/**
* Puts an object into the given bucket, within the given "folder" with the
* given content value.
*
* @param bucketName the name of the bucket
* @param folder the name of the "folder" to add the object to
* @param file the name of the object in the "folder"
* @param content the content of the object as {@link String}
*/
void putObject(String bucketName, String folder, String file, String content);
/**
* Lists all objects within the given bucket.
*
* @param bucketName the name of the bucket
*
* @return a List of Strings with the object keys in the bucket
*/
List<String> listObjects(String bucketName);
}GCSBucketService
public class GCSBucketService implements BucketService {
private Storage storage;
final static private String GCS_DOMAIN = "storage.googleapis.com";
public GCSBucketService(Storage storage) {
this.storage = storage;
}
@Override
public void putObject(String bucketName, String key, InputStream content, String contentType) {
try {
BlobInfo blobInfo = BlobInfo.newBuilder(BlobId.of(bucketName, key))
.setContentType(contentType)
.setCacheControl("no-cache")
.build();
storage.createFrom(blobInfo, content);
} catch (IOException e) {
log.error("Error putting object to GCS bucket: " + bucketName + " at key: " + key, e);
}
}
@Override
public List<String> listObjects(String bucketName) {
List<String> keys = new ArrayList<>();
Page<Blob> blobs = storage.list(bucketName);
for (Blob blob : blobs.iterateAll()) {
keys.add(blob.getName());
}
return keys;
}
}S3BucketService
public class S3BucketService implements BucketService {
private AmazonS3 amazonS3;
public S3BucketService(AmazonS3 amazonS3) {
this.amazonS3 = amazonS3;
}
@Override
public void putObject(String bucketName, String folder, String file, String content) {
putObject(bucketName, getKey(folder, file), content);
}
@Override
public List<String> listObjects(String bucketName) {
List<String> keys = new ArrayList<>();
ObjectListing objectList = amazonS3.listObjects(bucketName);
do {
for (S3ObjectSummary objectSummary : objectList.getObjectSummaries()) {
keys.add(objectSummary.getKey());
}
objectList = amazonS3.listNextBatchOfObjects(objectList);
} while (objectList.isTruncated());
return keys;
}Environment Config: S3 Bucket
bucketConfig {
bucketName: <BUCKET_NAME>
gcpProject: ""
key: <BUCKET_NAME>
awsRegion: <REGION>
}Environment Config: GCS Bucket
bucketConfig {
bucketName: <BUCKET_NAME>
gcpProject: <GCP_BUCKET_PROJECT_ID>
key: <BUCKET_NAME>
awsRegion: ""
}Advantages
- Reusability: The solution’s components can be utilized across various contexts and applications.
- Easy maintenance: Components are designed in a way that allows for straightforward upkeep and updates.
- Configurability: The solution can be easily configured and adapted to different environments or requirements.
- Streamlined app migration: Simplifies the process of migrating applications with reduced coding efforts.
- Cloud agnosticism: Enables operation across multiple cloud platforms without being tied to any specific provider.
- Hybrid mode compatibility: Supports running applications in a hybrid mode, accessing resources across cloud environments.
- Multiple cloud provider support: Offers the flexibility to incorporate implementations for multiple cloud providers as needed.
- Loosely coupled
Conclusion
As mentioned earlier, numerous methods exist for establishing connections to cross-cloud resources at runtime. However, this particular approach stands out due to its ease of implementation, maintenance, seamless integration with applications requiring minimal code alterations, and effortless switching between various cloud resources. Should you have any questions or comments, please feel free to share them. Your feedback is greatly appreciated.
About Kumaraswami
With over 17 years of experience as a Senior Engineer, Kumaraswami possesses extensive expertise in designing and implementing applications using Java/J2EE and Python. He is adept at crafting UI applications through Angular and React, establishing robust data pipelines, and architecting Google Cloud infrastructure.
Kumaraswami excels in orchestrating seamless migrations from on-premises systems to Google Cloud Platform (GCP), empowering organizations to leverage cloud-based solutions effectively.
His proficiency spans Java/J2EE, Python, Ruby, Groovy, Angular, React, Terraform, Chef, Helm, Docker, Jenkins, GitCI, Kubernetes, Apache Kafka, SQL, and cloud-native technologies. He particularly specializes in harnessing Google Cloud tools such as GKE, App Engine, CloudRun, Cloud Functions, DataFlow, Cloud Build, Secret Manager, VPC Service Control, IAM, GAR, VPC Service Control, BigQuery, Cloud SQL, GCS, and Pub/Sub.
About SADA, An Insight company
SADA, An Insight company, is a global cloud consulting and professional services market leader providing solutions powered by Google Cloud. Since 2000, SADA has helped organizations in healthcare, media, entertainment, retail, manufacturing, and the public sector solve their most complex digital transformation challenges. SADA has offices in North America, India, the UK, and Armenia, providing sales, customer support, and professional services. In addition to being Google’s leading partner for generative AI solutions, SADA’s expertise includes Infrastructure Modernization, Cloud Security, and Data Analytics. A 6x Google Cloud Partner of the Year award winner with 10 Google Cloud Specializations, SADA was recognized as a Niche Player in the 2023 Gartner® Magic Quadrant™ for Public Cloud IT Transformation Services. SADA is a 15x honoree of the Inc. 5000 list of America’s Fastest-Growing Private Companies and has been named to Inc. Magazine’s Best Workplaces four years in a row. Learn more: www.sada.com.
If you’re interested in becoming a part of the SADA team, please visit our careers page.

